Adrián Javaloy
Adrián Javaloy
Home
Publications
CV
Light
Dark
Automatic
Normalizing flows
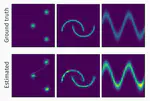
Relative gradient optimization of the Jacobian term in unsupervised deep learning
By using relative gradients we propose a new approach for exact training of neural networks where the log-determinant of the Jacobian appears in the loss function as it happens, e.g., in normalizing flows.
Luigi Gresele
,
Giancarlo Fissore
,
Adrián Javaloy
,
Bernhard Schölkopf
,
Aapo Hyvarinen
PDF
Cite
Code
arXiv
Cite
×